
創薬AI開発のための学習データ作成に新視点、失敗例を1000倍学ばせると誤分類が100分の1以下に 関西医大らの研究

創薬におけるAI開発の進展は、開発費用の削減や高度化の視点から大いに期待されているが、日本の研究グループが、AI開発時に必要となる学習データに焦点を当てた新しい研究成果を発表した。これまで使われていない非活性化合物が含まれたデータを学習データに取り入れると、AIの正答率が劇的に向上したという。
非活性化合物のデータを組み込むことで予測精度向上
研究成果を発表したのは関西医科大学附属生命医学研究所 分子遺伝学部門の木梨達雄教授と池田幸樹助教、摂南大学薬学部化学系薬学分野の表雅章教授、河合健太郎准教授らの研究チーム。創薬研究において近年、AI活用による化合物探索の効率化が試みられ、その学習方法についてはディープラーニングなど多くの方法論が提案されているが、学習データに着目した研究はほとんどみられないという。また、一般の創薬手法で用いられる「High Throughput Screening (HTS)」ではヒット率が 0.1%以下にとどまると言われており、これまでの創薬では数少ない「Hit 化合物のみ」に着目し、それ以外の数多く得られる「失敗したデータ群」については十分に活用されていないとする。
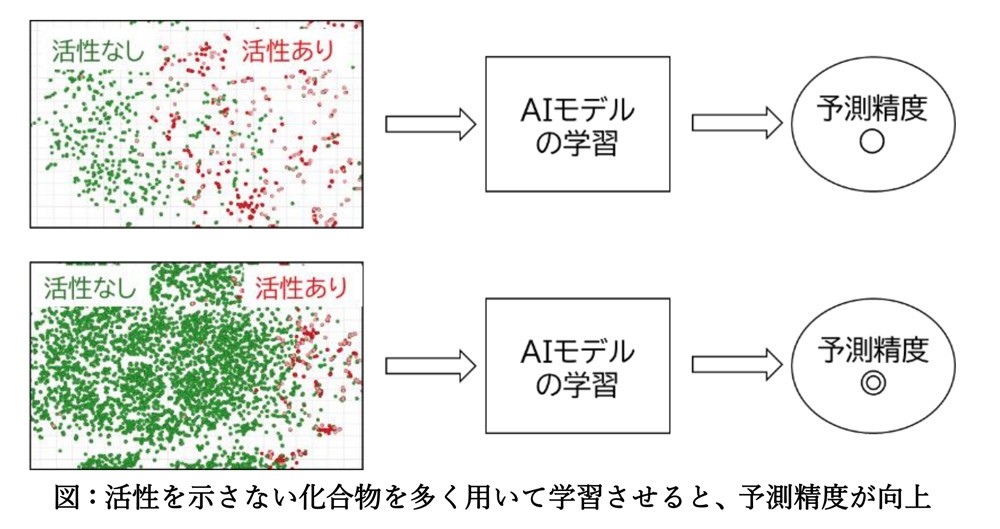
研究チームでは、この「失敗したデータ群」の特徴、つまり「化合物の大部分が活性を示さない」という点に着目。血栓の原因であるインテグリンαIIbβ3を阻害する化合物をAIで探索するというテーマ設定で、その学習データの構成を様々に試した。従来手法より、活性を示す化合物(正例)に対して活性を示さない化合物データ(負例)の割合を 1,000倍増やすと、AIの誤分類が100分の1以下となって識別能力が格段に向上したという。
研究チームではこの知見を利用することで、より少ない検証回数や薬剤リソースでスクリーニングを行うことが可能となり、創薬研究における大幅なコストダウンに繋がる幅広い応用が期待できるとしている。なおこの研究成果は学術誌の「molecular informatics」(インパクトファクター:2.741)に2021年3月18日付で掲載されている。