
【園生智弘コラム】ITを活用したこれからの臨床研究 ①〜気合のデータ収集からの脱却〜

臨床研究のあり方はIT技術の拡大に伴い急速に変革しています。
本シリーズ記事では、この変革を、医療データの最前線の取り組みに絡めて概説していきます。これからの臨床研究を手がける研究者にとって有用な情報提供となりましたら幸いです。第1回の本記事では、研究データ収集の戦略について触れたいと思います。
*本記事内容の一部は2019年夏に慶應義塾大学にて行われた第25回臨床研究推進啓発セミナーの講演内容及び月刊救急医学2019年12月号の寄稿「ビッグデータと救急・集中治療(園生智弘・中村謙介)」を踏襲しています。*
気合のデータ収集からの脱却
臨床研究において、質と量の担保されたデータの収集は極めて重要です。このデータ収集戦略において、「気合と根性の人力データ収集」が蔓延しているのは憂慮すべき事態です。昨今は「既存ビッグデータベースの統合」や「Webアプリケーション等を業務展開することとセットのデータ収集」といった手法も広がってきました。
人力のデータ収集には絶対的な限界が存在します。初期の戦略策定を間違えると、20人の人力で膨大なコストをかけて3年かけて収集したデータの10倍ものデータを、数人の後発研究グループが構築したデータ収集プログラムを用いてわずか10分で収集されるといった悲劇が起こります。戦時中にあったとされる「竹槍でB29を落とす」ような無謀な努力を、ビッグデータ研究で繰り返してはならないと考えます。
臨床研究におけるIT利用のポイント
臨床研究におけるIT利用戦略と言ってもピンと来ない方が多いかもしれません。具体的には、下の図のようなイメージです。3つの要素に分けて解説します。
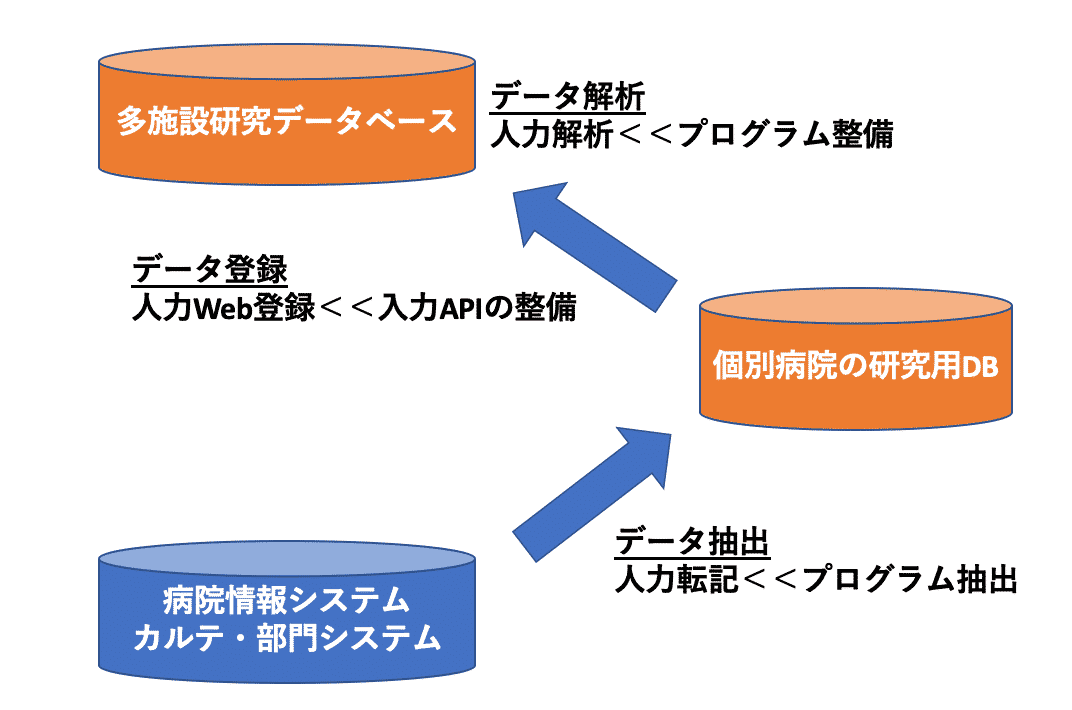
①データ収集
いまだに病院電子カルテからのデータ抽出を研究者が手動のエクセル転記で行なっているケースが多いです。「カルテからのデータ抽出には何千万もかかる」という都市伝説を信じきっている研究者もいます。実際に研究者が単独でデータ抽出を依頼する場合は様々な困難が発生します。電子カルテベンダーとの契約(大手ベンダーでカルテデータの内容開示に機密保持契約が必要です)、これに伴う費用が発生する場合もあります。
しかし、通常、大手カルテベンダーはデータ抽出用のDWH(データウェアハウス)を実装しており、原則無料でアクセス可能です。それでも、カルテのバックデータベースは歴史的経緯もあり相当統一性を欠いています。例えば、同じ「PT-INR」を表すフィールドコードはベンダーにより異なるのです。データベースの取り扱いに慣れていないと取り出したデータの扱いや欲しいデータの格納テーブルの特定に苦慮しますが、医用工学研究所のCLISTA!®︎をはじめとしてここを理解しやすくする市販のDWHアプリケーションもあります。これらのDWHは病院予算で導入している場合もあり、研究用のデータ抽出にこれを使わない手はありません。
しかし、残念ながら現場の医師・研究者がDWHの存在を知らないことが非常に多いです。研究計画を立てたのち、Excelに打ち込む人員を確保する前に、このような気の利いたデータ抽出方法を医療情報部門に交渉しつつ最大限検討することが重要です。私どもの運営するTXP Medicalはこのような交渉を個人の先生方に代わって行なっているケースも多いですし、院内DWH構築を直接受注しているケースもあります。個人の研究者単位の依頼ではなかなか病院が動いてくれない場合もありますが、病院提携ベンダーである当社がしかるべきルートで依頼することで、簡単に道が開ける場合もあります。
②データ登録
多施設研究のデータ登録において、もっとも一般的なのが「Webフォーマットによるデータ登録」です。院内のデータをせっかく綺麗に集めても、Webフォーマットへの入力が手作業だと、この入力部分にかなりの労力を要します。
今後の多施設研究において、このデータ入力部分の自動化は重要な要素だと考えられます。入力APIと図1で記載しているAPIというのはApplication Program Interfaceの略で、簡単にいうと「プログラム・ソフトウェア同士でデータをやりとりする仕様」となります。ここで挙げた多施設研究の事例では、「規定の順序にデータが並んだCSVファイルを各施設からアップロードすれば中央データベースでのデータ登録が完了する」ような仕組みを用意する、ということです。
このようにすることで初めて、各施設のデータベースを強化することにより多施設研究のデータ登録がきわめて容易になります。結果として院内データベース構築に力を入れている各協力施設の研究協力を得やすくなります。この点において、日本集中治療医学会のJIPAD (参考記事) は各施設にデータ登録用のFileMakerファイルを配布するという点で秀逸なスキームです。
③データ解析
データ解析段階においては、研究者が最低限のデータベース知識を持つことは重要です。FileMaker®️、python®️、R®️、あるいはExcelのマクロでも良いですが、最低限のプログラムを書けることは、これからの臨床研究者には必須スキルです。なお、このプログラムを書ける、ということは専門家レベルである必要は全くありません。「正規化データを非正規化して並べかえる」、「重複データをチェックしてフラグを立てて重複削除をする」くらいのことができれば十分でしょう。
もう一つ解析段階で重要なことは、プログラムの共有知化です。個別の研究者・研究グループレベルでデータクリーニングや解析プログラムを内製するとあまりにも時間がかかります。オープンソースで公開されたプログラムを検索して利用したり、研究グループ間でこれらのナレッジを共有できるスキームがあるのが望ましいと考えられます。TXP Medicalリサーチチームでは、例えば「診断名」や「既往歴」の表記揺らぎに満ちたデータ群に対して、辞書を用いてICDコードを付与し、「感染症かどうかと感染巣」「悪性腫瘍病名か否か」「Charlson Index」などを自動で弾き出せるプログラムをメンバー同士で共有しています。
まとめ
臨床研究におけるデータ収集トレンドの変化につき概説しました。
臨床研究というゲームのルールが変化している中、生き残るのは常に変化に対応出来る者です。次の第2回の記事では、研究チーム・実施体制について書こうと思います。
寄稿:園生智弘(そのお・ともひろ)
TXP Medical 代表取締役医師。
東京大学医学部卒業。救急科専門医・集中治療専門医。
東大病院・茨城県日立総合病院での臨床業務の傍ら、急性期向け医療データベースの開発や、これに関連した研究を複数実施。2017年にTXP Medical 株式会社を創業。2018年内閣府SIP AIホスピタルによる高度診断・治療システム研究事業に採択(研究代表者)。日本救急医学会救急AI研究活性化特別委員会委員。全国の救急病院にシステムを提供するとともに、急性期医療現場における適切なIT活用に関して発信を行っている。TXP Medical 代表取締役医師。