
個人情報を保護し、かつ高精度なゲノム配列推定法を開発 東北メディカルメガバンク機構

東北メディカルメガバンク機構は、多人数の個人全ゲノム情報(参照パネル)を用いることなく、ディープラーニングによって全ゲノム配列を推定できる新たな手法を開発したと発表した。従来の手法よりも高精度としており、参照パネルを用いることができない研究機関でも活用可能となることで、遺伝医学の大きな進展が見込めるとしている。
個人情報を保護しながら配列推定が可能な「RNN-IMP法」
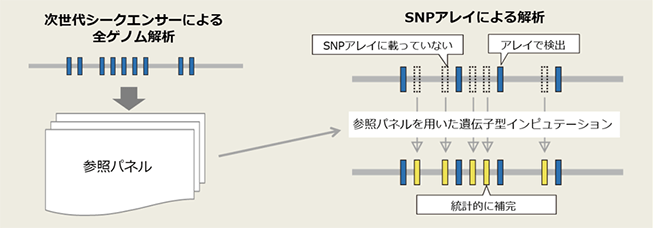
今回同機構が開発したのはRNN-IMP(Recurrent Neural Network – IMPutation)法と呼称する新しい遺伝子配列推定法。遺伝子変異による疾患発症リスク予測などでは、ゲノム情報取得のための計測技術としてSNPアレイが一般的に用いられるが、SNPアレイでは、各個人の遺伝子変異情報の計測を安価に行うことができる一方、取得できる遺伝子変異情報は予め設計されたものに限られる。このためSNPアレイを用いた解析では、計測された遺伝子変異情報から未観測の遺伝子変異情報を推定する「遺伝子型インピュテーション(遺伝子配列代入)」により、擬似的に全ゲノム配列の推定を行うことが一般的となっている。
従来の遺伝子型インピュテーション手法では「Li and Stephensモデル※1」と呼ばれる遺伝学の理論モデルに基づき、参照パネルを構成する多検体の全ゲノム配列を用いて未観測な遺伝子変異情報の推定が行われている。
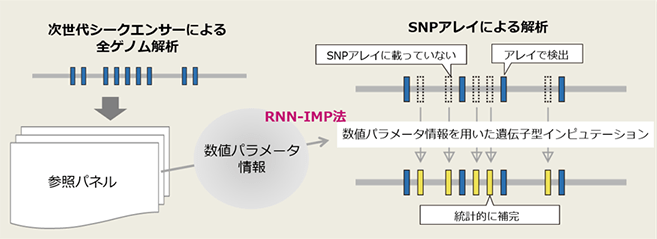
今回、同機構が開発した「RNN-IMP法」では、参照パネルの情報を数理モデルのパラメータとして学習することで、個人識別が困難な形で保持し、遺伝子型インピュテーションを行う。このため、個人情報漏えいのリスクを気にすることなく、公共データとして共有することが可能となる。
個人情報を保護した状態で、従来手法より高精度な配列予測を実現
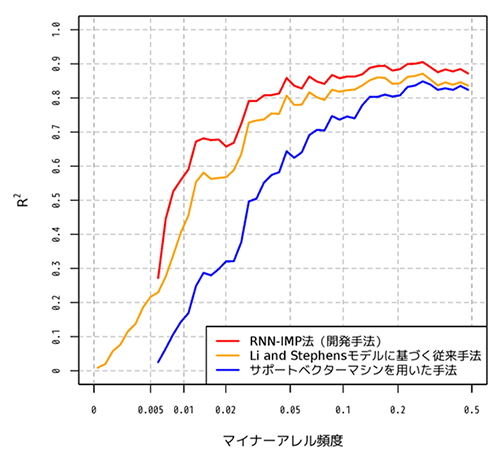
形でしか利用できない条件のもと、東アジア人集団を対象とした遺伝子型インピュテーションの推定精度を検証した結果
同機構では開発した手法の効力を検証するため、1000人ゲノムプロジェクト※2で公開されている参照パネルについて、東アジア人集団の参照パネル情報が「個人情報保護の観点から個人識別が困難な形でしか利用できない」という条件を設定し推定精度を検証した。検証の結果、Li and Stephens モデルに基づく従来手法では、参照パネルを全て利用できないことから遺伝子型インピュテーションの推定精度が低下したのに対し、個人識別が困難な形で全ての参照パネル情報の利用が可能な RNN-IMP 法が、より高い精度での遺伝子型インピュテーションが可能であることを確認した。
同機構では本成果により、個人情報保護上の懸念を払拭して、多くの研究機関で高精度な遺伝子型インピュテーションが可能になり、遺伝医学の進展に大きく貢献できるとしている。なおこの成果は米国東部時間2020年10月1日付で、英国科学雑誌「PLOS Computational Biology」のオンライン版に公開された。
※1 Li and Stephensモデル
ある個人の全ゲノム配列は、その他の個人の全ゲノム配列の組換えと少数の突然変異で表現が可能であるとする遺伝学の理論モデル。既存の遺伝子型インピュテーション手法はこの理論に基づき、参照パネル内の全 ゲノム配列の組換えで対象検体の全ゲノム配列を推定し、遺伝子変異情報の推定を行っている。※2 1000人ゲノムプロジェクト
複数の民族集団から構成される1,000 を越える検体を対象とした、全ゲノム配列情報の計測と遺伝子変異情報の網羅的な解析を行う国際研究プロジェクト。2008年1月より開始されており、現在、2,504 検体について各検体の全ゲノム配列と遺伝子変異情報等が公開されている。